

The Unexpected Flaw in Ai21’s Jamba Model
Read about how Ai21 can improve the Jamba model by fixing a simple architecture error derived from Mamba research.


The hottest new model on the block has to be the new hybrid model Jamba. While everyone has been talking about which General Sequence Model will be king, Mamba or the Transformer, the intelligent researchers at Ai21 realized that we don’t have to choose. The Jamba model, using both Transformer layers and Mamba layers takes a “best of both worlds” approach, gaining the increased performance from the Transformer’s great associative recall, while taking full advantage of Mamba’s efficient processing to get a low latency, high context length model that is both practical and intuitive. And that is how I felt about their recent white paper announcing the model, practical and intuitive while being far more informative than what we’ve become accustomed to with professional research. However, there was one design decision within Jamba that conflicts with existing research which I wanted to discuss here today. I bring up what I perceive to be a potential oversight by the Ai21 research team, not to criticize or lampoon, but to aide in the scientific process. In fact, I believe that should this oversight be true, the Jamba model could be much more performant without much architectural difference.
The Jamba Model
The new Jamba model ushers in the era of the Hybrid LLM. While no one can be certain how long this era will last, the Jamba model provides an elegant marriage of the latest trends in AI, combining the new Mamba model with the trendy Mixture of Experts model and the timeless Transformer model. All three of these components are paired together along with some classic multi-layer perceptrons (MLP) to create various layers used to construct the Jamba Block.
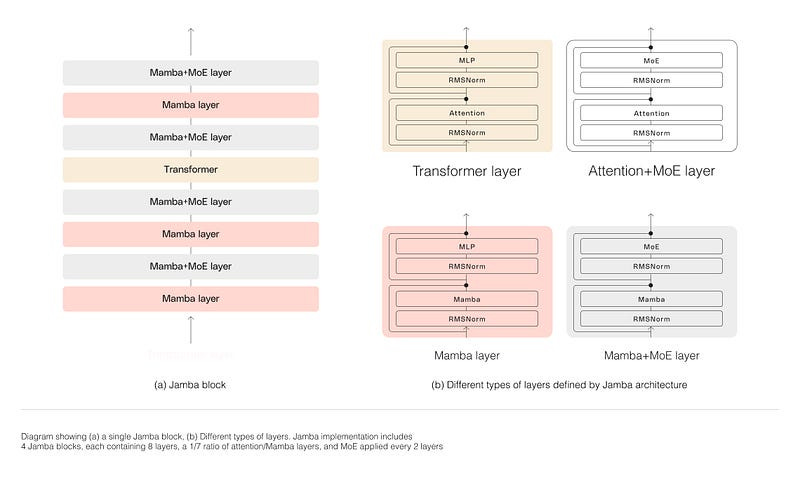
The Transformer layer follows the same format as all of the latest encoder-only Transformer models, using RMSNorm in place of the original LayerNorm, and using an Attention cell followed by an MLP. The same general format is used for the Attention+MoE layer, but the MLP is replaced with a MoE cell. Both of these implementations are well tested and well understood. Their use here, while important, does not require much scrutiny. The two more interesting layers are the Mamba layer and the Mamba+MoE layer, which follow the same format as their Attention counterparts with a simple Mamba substitution. These layers are more interesting because we simply do not have the same wealth of information gathered from studying them for years. The Transformer has been the best language architecture for nearly 7 years, meaning we have 7 years worth of research advantage when understanding the Transformer compared to Mamba. And this is where I think the author’s of Jamba may have made on oversight.
The Glaring Oversight
One of the great things about the Mamba paper was the number of ablations run by the authors. They understood the knowledge gap that Mamba would have to overcome to be talked about next to the Transformer, and as such, they placed the Mamba cell in many different language model architectures. One of the more interesting findings was that when Mamba was interleaved with MLPs, alternating back and forth between the two cell types, the model actually performed worse than a language model of the same depth that used purely Mamba cells.

And this discovery was further backed up by the work of MoE-Mamba, one of the earliest papers to experiment with the combination of Mixture of Experts with Mamba. In this paper the authors discovered that MoE-Mamba performed worse than a basic Mamba model when the number of experts was small, especially in the degenerate case where there was a single expert (i.e. an MLP). These two scientific statements are in direct conflict with the Mamba layer used within the Jamba architecture, and imply that the Mamba layer should in fact be a sequence of two subsequent Mamba cells with no MLP whatsoever.
It is worth noting, however, that the findings in the Mamba and MoE-Mamba papers may not be absolute. Both papers work on relatively small scales when compared to Jamba, a 52B parameter model, and both papers rely heavily on perplexity as their evaluation metric. This reliance on perplexity is actually one of the reasons why Mamba was rejected from ICLR, as it is not necessarily an accurate indicator of down-stream task performance. So, this is where I leave room for the Jamba authors to have actually found the correct implementation. Should large scales and/or more accurate evaluation metrics provide sufficient evidence to counter the claims made in the papers above, I think it is only right that the researchers at Ai21 post these findings. Results like this would provide great insight into a novel architecture such as Mamba and help developers understand how to build models around Mamba. And if my hypothesis, that there was a small oversight in the construction of Jamba, prove truthful, I think it is also worth the discussion. Not only because it can help out the scientific community, but because it could even lead to a more performant Jamba model.
Conclusion
While I believe that the Jamba architecture presents a slight error in their construction of the Mamba layer, I am wowed by their current down-stream task results and corresponding efficiency. I fully believe that the Jamba model is here to usher in a new crop of hybrid LLMs that provide yesterday’s results at a much lower cost, and I fully believe that the correction of this minor oversight could lead to even further performance gains. Again, the purpose of this post is to participate in the scientific method so that the scientific community can benefit as a whole. If you have any desire to answer some of the questions posed here please let me know what results you find as the answer is certain to be fascinating.
If you enjoyed this post consider reading some of my other content. I release two articles every month and write about AI philosophy, Programming Project, and Paper discussions. This post was unexpected and was written in addition to my two posts for this month so my upcoming posts and post schedule remain the same as before:
Practical Programmable RAG Parts 1 and 2
Creating Mixture of Experts From Scratch
How to Steal an LLM
If any of these topics seem interesting to you consider following me here on Medium or on my Substack (I post the same content to both platforms for free). I post twice a month on Mondays, covering topics such as AI research papers, AI philosophy, and AI programming projects.