



This Will Fix Your Multi-Modal Model
Using masked training to improve multi-modal emotion recognition models.


As AI researchers aim to create Artificial General Intelligence (AGI) we face a huge hurdle of integrating disparate data sources into one effective model architecture. It is incredibly challenging to create a robust representation that is able to encapsulate the data within each modality, adequately extracting information while generalizing to data sparse environments. This blog post explores my research into the realm of multi-modal models with a focus on a fascinating application: multi-modal emotion recognition.
Bridging Modalities: Knowledge Distillation and Masked Training for Translating Multi-Modal Emotion…
This paper presents an innovative approach to address the challenges of translating multi-modal emotion recognition…arxiv.org
While multi-modal emotion recognition models have shown remarkable prowess in capturing the nuances of human emotions through the integration of diverse data modalities, their susceptibility to failure when presented with partial modality data unveils a significant challenge. These models rely on a holistic understanding derived from the synergy of text, image, and audio inputs, and when confronted with incomplete information from any modality, the intricate interplay of contextual cues becomes disrupted, hindering the model’s ability to extract the full spectrum of emotional information. In such instances, the model may struggle to comprehend the emotions expressed through various channels. Addressing these limitations is pivotal to advancing the reliability and robustness of multi-modal emotion recognition in real-world applications.
This behavior lies in stark contrast to human cognition, where the presentation of partial data does not dramatically inhibit our ability to recognize emotions. Humans have an ability to flexibly intake a vast array of possible input modalities and can even improve their understanding of individual modalities through an effect called multi-modal grounding. Multi-modal grounding in the context of emotion recognition uses the existence of multiple modalities for a more holistic understanding of human emotions. By integrating information from multiple sources, one can anchor emotions in a broader context, using one modality to eliminate misunderstandings in another. This approach recognizes that emotions are inherently multi-faceted, often expressed through a combination of spoken words, facial expressions, and body language. Through cross-modal associations, multi-modal grounding enhances the model’s capacity to discern subtle emotional nuances that may be obscured when analyzing individual modalities in isolation. As we delve into the realm of multi-modal grounding for emotion recognition, the promise lies in unraveling the intricate layers of human emotional expression, creating a more nuanced and accurate representation of our complex interplay of feelings across various sensory dimensions.
In our work, linked at the top of this article, we initially set out to explore this multi-modal grounding effect by running experiments to see if we could use a multi-modal model to generate a highly performant audio-only emotion recognition model. The results we came across through this research proved much more interesting, showing that multi-modal models are not experiencing grounding effects and are failing to extract critical information from the modalities they are given. This blog post will delve into these results and the training routine used to improve information extraction.
COGMEN
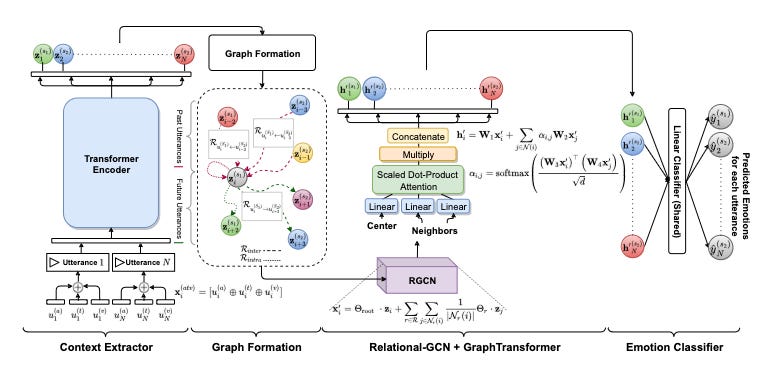
As our work has focused on training we incorporate the state-of-the-art COGMEN architecture as a benchmark. Renowned for its excellence in multi-modal emotion recognition on the IEMOCAP and MOSEI dataset, the COGMEN architecture comprises three pivotal components designed to capture and leverage the inherent inter-modal dependencies present in emotional expressions.
The first component involves a transformer-based feature extractor, strategically employed to capture intricate intra-utterance dependencies. This crucial element plays a pivotal role in extracting high-level representations from input data, enabling the model to discern nuanced patterns associated with diverse emotional states.
The second component introduces a Graph Neural Network (GNN), where utterances are interconnected with their i-predecessor and j-successor utterances in time, forming a temporal graph that encapsulates the dynamic evolution of emotions throughout a conversation. This structural framework empowers the model to harness the temporal context and relationships between utterances, thereby fostering a more comprehensive understanding of emotional dynamics. Notably, in both our experiments and the original COGMEN paper, i and j are both set to 5.
The final component in the COGMEN architecture is a simple classification head which is a fully connected network which will output the various emotion classes. For our experiments we are working with IEMOCAP4, meaning the classification head will predict between happy, sad, neutral, and angry. Additionally we will only be working with the audio and video modalities to replicate human emotion recognition more accurately.
Masked Training

It turns out that the key to multi-modal grounding and improved information extraction is frustratingly simple, masked training. In our implementation of masked training we stochastically sample one of 4 input occlusions. The first occlusion, sampled with a probability of 10%, is no occlusion where the input is freely given to the model during the current training step. The next two occlusions, both sampled with a probability of 30%, are total modality occlusions where audio or video is completely masked before the input is passed to the model. Lastly, with a probability of 30%, we randomly occlude frames within the input. Under this policy each frame is masked with a probability of 20% in both the audio and video domains.
This method of randomly masking the input is simple but surprisingly effective. While we cannot fully explain why this training method in fact provides multi-modal grounding, one intuitive answer is that the training forces the model to look at other modalities in order to clarify areas of uncertainty that are forced upon the model through these stochastic input masks.
Unfortunately, as with all things in machine learning, there is no free lunch. While this training method is intuitive and simple to understand and implement, it introduces a host of hyper-parameters that can be frustrating to tune as model size and modality quantity increases. Selecting adequate probabilities for each input occlusion as well as selecting accurate frame masking probabilities and even frame masking sizes amounts to 7 additional hyper-parameters in our audio-video context. The only solace is that these parameters are all bounded in nature, however, even this may provide little help on a larger model.
Results
For our results we analyze the COGMEN-A (audio-only COGMEN) and COGMEN-AV (audio-video COGMEN) on both audio-video and audio-only contexts against a COGMEN-AV model that has been trained using our masked training routine which we will call COGMEN-Mask. In addition to this we choose to analyze the performance of each of these models without the benefit of the GNN by setting i and j (the temporal graph parameters) to zero, thus reducing the GNN to a fully connected layer. Lastly, to confirm the existence of multi-modal grounding, we benchmark against a mask trained COGMEN-A model as well.

It is clearly show that the COGMEN-Mask model outperforms all benchmark models in both audio-video and audio-only contexts, showing great improvement when given partial modality information. We also see the COGMEN-Mask model outperform COGMEN-A both with and without masking, strongly implying that the model in fact uses multi-modal grounding to achieve these performance increases. Additionaly, the COGMEN-Mask model shows similar performance gains with or without the benefit of the underlying temporal graph and GNN, indicating that the GNN is non-critical to the performance gains provided through masked training.
Conclusion
Our exploration into multi-modal emotion recognition has shed light on the inherent challenges faced by existing models and presented a promising solution to enhance their performance. The conventional approach, relying on holistic integration of text, image, and audio inputs, often falters when confronted with partial modality data, hindering the models’ ability to capture the full spectrum of emotional information. Drawing inspiration from human cognition and the concept of multi-modal grounding, we introduced the COGMEN architecture and a masked training routine to address these limitations.
Our results unequivocally demonstrate that the COGMEN-Mask model surpasses benchmark models in both audio-video and audio-only contexts, showcasing significant improvements when presented with partial modality information. This success strongly suggests that the model effectively employs multi-modal grounding to enhance its understanding of emotions. Surprisingly, the performance gains persist even without the inclusion of the Graph Neural Network (GNN), indicating that the masked training routine itself plays a crucial role in overcoming the challenges posed by partial modality data.
While the simplicity and effectiveness of masked training are evident, we acknowledge the introduction of additional hyper-parameters, posing challenges in tuning for larger models. Despite this, the notable advancements in performance underscore the potential of this approach to revolutionize multi-modal emotion recognition. Our findings open the door to further exploration and refinement of masked training methodologies, paving the way for more robust and reliable multi-modal models in the realm of artificial intelligence.