

Mamba’s Next Steps (or Slithers)
Mamba has already inspired large amounts of research. From language to vision Mamba is revolutionizing artificial intelligence.

Mamba’s Next Steps (or Slithers)

Since the announcement of Mamba the Machine Learning community has been on fire, awaiting results of a large scale, billion parameter, Mamba language model. But researchers have not sat idly by waiting for the few organizations with large enough compute resources to analyze Mamba, instead looking to employ the new SSM architecture in every conceivable way possible. In this blog post we will look at the research that has been inspired by Mamba and see how Mamba is already revolutionizing the field of Machine Learning.
Mixture of Mamba
Mixture of Mamba seeks to combine the Transformer Mixture of Experts (MoE) layer with the Mamba S6 layer. For those without knowledge of MoE, the MoE layer replaces the singular feed-forward network in a Transformer with a router that chooses between several “expert” networks. In the canonical MoE layer these experts are duplicates of the vanilla feed-forward network from the base Transformer.
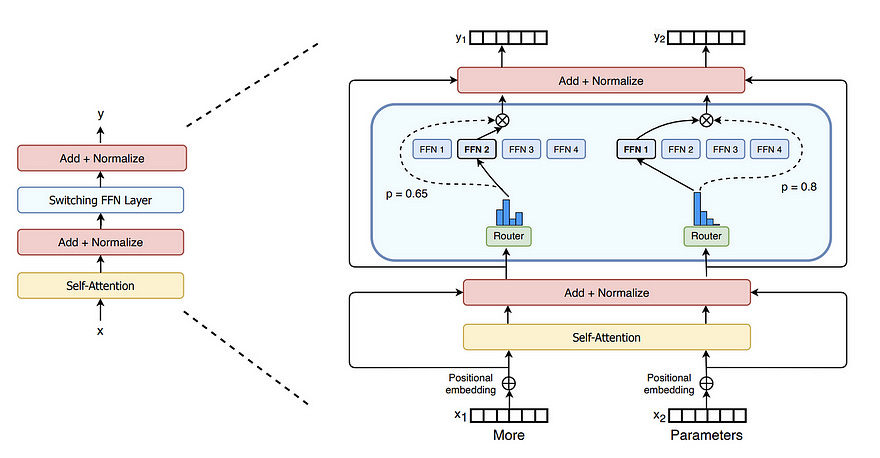
While this adjustment may seem basic, it allows for scaling of model parameters without equivalent scaling in compute requirements. This essentially means free performance increases with little to no costs, so of course it is natural to apply this MoE layer to Mamba. This paper does this by simply replacing the Attention layer within the Transformer MoE with a Mamba layer, and the results are promising. As with everything Mamba the parameter scales are far from large enough, but the early results show much quicker convergence than any other Transformer or Mamba architecture in existence.
The most interesting component of this research is that it seemingly contradicts some of the findings in the initial Mamba paper. In the initial paper, Mamba’s authors tried alternating Mamba layers with feed-forward networks similar to the Transformer architecture and actually found that performance degraded, however, this paper shows that MoE layers are strong enough to counter this performance degradation and even increase convergence. With all of the excitement around both Mamba and MoE it is really interesting to see the two combined even if the scale and benchmarking done may leave something to be desired.
U-Mamba
The Mamba architecture is, at its core, derived from a convolution. This means that some of the most exciting implementations of Mamba seek to use it as a plug-in-place for convolutional layers. U-Mamba is a descendant of not only Mamba, but U-Net, a convolutional architecture for image segmentation.
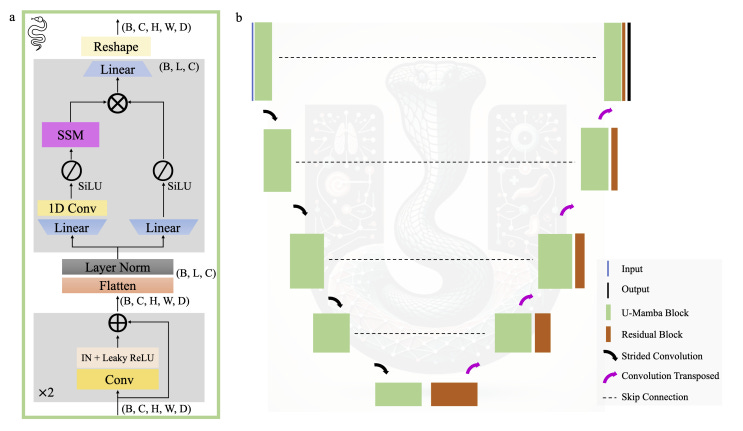
The authors of U-Mamba found that this simple adaptation of U-Net caused increases in performance on medical imaging tests (MRI, CT Scans, etc.) when compared to its predecessors. This is a great step as medical imaging has been one of the great computer vision tasks that the Transformer has not been able to revolutionize. The author’s even mention that it is likely that the Mamba architecture could absorb more data, allowing it to perform even better than traditional CNN approaches and may be able to aid in areas where modelling long-range dependencies is necessary.
VisionMamba
Mamba, being designed for the task of language modelling is a 1-D sequence model. The authors of VisionMamba look to change that, aiming to create a 2-D adaptation of Mamba that can more accurately model images. Luckily, the path for doing so was well laid out by the VisionTransformer (ViT). To accomplish this transformation the authors of begin by segmenting the input image into patches of 16x16 pixels. These patches are then flattened and given positional embeddings to form input tokens which are passed to the Mamba encoder.
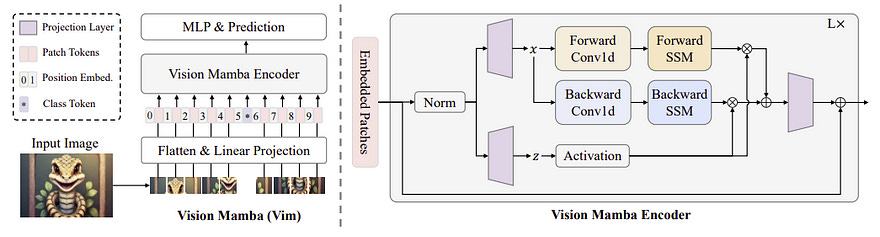
The use of the Mamba architecture instead of a Transformer architecture creates a substantial gain in compute costs. Because of the dimensionality of images it is often expensive to try and perform quadratic attention computations across an entire image. Mamba’s sub-quadratic scaling removes this issue entirely, allowing the model to feasibly scale to gigapixel image scales. Efficient compute, however, is far from the only benefit. Based on the paper VisionMamba generates competitive or better performance than ViT and DeiT Transformer models while often using far fewer parameters.
MambaByte
MambaByte aims to take advantage of Mamba’s efficient context window scaling in order to create a token-free language model. The goal of token-free language models is to learn directly from the bytes used to represent language rather than using tokens and large vocabularies to simplify language interactions. These tokens can often lack robustness to typos and spelling variations, implying the potential need for byte-level language modelling.
And the papers results show that Mamba excels at this task. Given the task necessitates a large context window and requires some level of long-range knowledge Mamba is perfectly suited to this task. The MambaByte model shows great performance and computational efficiency on both language modelling perplexity and language generation on this byte-level task. All of these results, however, are somewhat expected. This to some degree the very problems that Mamba was designed to solve so it is truly inspiring to see Mamba solve something previously so challenging.
Conclusion
While some of these applications of Mamba may seem straightforward, there is just so much about Mamba we do not know. We require papers like these to begin to help us understand when and where Mamba should be applied and how Mamba truly works. The information from these papers is vital when designing future benchmarks and determining where vital research resources should be deployed. While it is quite possible that the answer to the question, “Where is Mamba useful?” will be everywhere, but as of right now it appears that Mamba is most reasonably applicable in high frequency environments or environments where CNNs are a dominating force. There is still much more research that will be needed to truly understand Mamba if it is to become the next great model architecture, but early results seem promising enough to inspire more research.
Personally, I am not sure if Mamba’s strengths will lie in language modelling, where it is currently being applied. The initial SSM architectures like S4 were designed to address long-range data dependencies and handle high frame-rate/continuous data often present in medical signal and speech waveforms. While early results show promise for Mamba in nearly every sequence modelling domain, I think that Mamba may be most effective in the same long-range high frame-rate domain as its predecessors. I hope that future iterations of Mamba seek to return to this area and analyze what effect Mamba can truly have. While language modelling is currently the hottest field in AI, it is far from the only area AI can make an impact.