



Mamba Will Never Beat the Transformer
New research has improved Transformer Context Length, creating new models such as Gemini 1.5, solving a key weakness for Transformers.

Mamba Will Never Beat the Transformer

Mamba has dominated AI water-cooler talk for the past 2 months with many claiming that it may well defeat the Transformer and its crucial attention mechanism. While Mamba has shown some of the key properties of a “Transformer Killer”, two new papers have dashed many hopes for a Mamba takeover by expanding the Transformer’s context window. And we have likely already seen the effects of these aforementioned papers in the development and release of Gemini 1.5, a new AI model from Google which can beat OpenAI’s GPT4 on certain benchmarks thanks to its gigantic context window. Based on reporting, Gemini 1.5’s context window nearly 8x the context window of GPT4 (1M vs. 128k), allowing Gemini to take entire movies as input, drastically improving document size limitations. In this blog post we will discuss why this giant context window is important and why it may make Mamba obsolete.
Context is Everything
So why has the Transformer’s context window been so limited, why is removing this limit helpful, and why does this hurt Mamba’s ability to replace the Transformer? This limited context window is related to the Transformer’s Attention computation, while “Attention [may be] all you need”, it turns out that this operation is quite expensive in regards to context length. Because attention is calculated for all token pairs, the operation is quadratic in nature, fine for small contexts and large compute budgets, but intractable and time consuming for any context lengths over a certain size.

While researchers can work with clean data that fits within these context window constraints, real-world data encountered by ChatGPT and Gemini will not always have such a small necessary context. If we were to increase the size of the context window without adversely affecting compute requirements we could allow agents like ChatGPT and Gemini to remember entire conversation histories, or even all the interactions a user has had with the AI agent. This could create remarkable improvements to response accuracy and could drastically decrease hallucination. Context provided through RAG could grow to ensure the encapsulation of necessary data, decreasing the need for well engineered document chunking. Just by removing the limitations set by the context window we have opened the door to drastic AI performance gains.
And Mamba, in part, aimed to solve this issue, trying to create a language model architecture on par with the Transformer without its quadratic Attention computation. While Mamba deserves its own full explanation, its Attention equivalent can be thought of as something more akin to Memory. While Attention performs a direct lookup of all tokens in the sequence, Mamba’s Memory simply aims to distill token information in a sequential manner similar to an RNN. This allows Mamba to perform well on Long-Range tasks which require giant context windows. Tasks such as document summary or even conversation recall are rather trivial for Mamba, making it an attractive architecture. However, if a Transformer architecture could already address the issue of growing context windows, it would be hard for Mamba to remain viable. The amount of research hours spent trying to understand the Transformer, the volume of hardware specifically tuned to perform Attention computations, and the giant code base that make implementing the Transformer quite simple all act as gatekeepers to Mamba’s success. And on top off all of this, the Transformer’s direct lookup will always provide better theoretical recall than Mamba’s Memory can offer, meaning Mamba will likely be unable to even best the Transformer on performance.
So then, how has the Transformer done this? How has the Transformer conquered context?
Ring Attention
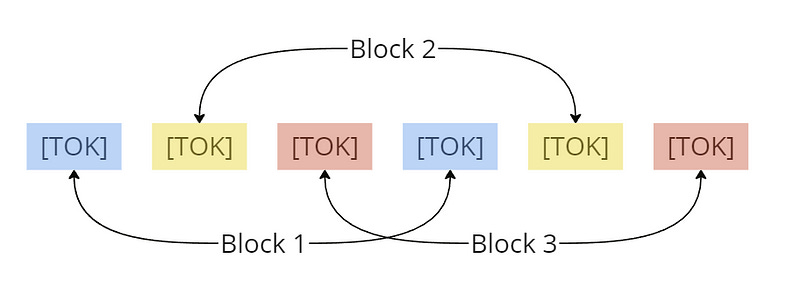
The first paper to bring about this context revolution introduces Ring Attention. The work behind Ring Attention is surprisingly simple, building upon the idea of Blockwise Attention computation, where the total Attention computation can be broken up into subsections that can be computed efficiently in memory. The scheme for Blockwise Attention requires an initial intra-block Attention Calculation, followed by a sequence of inter-block Attention Calculations.

These intra- and inter-block calculations are done for each block and saved away while the next calculation is done. Once all of the Attention calculations are complete they can be reloaded and passed further on into the network. The key problem with this method, which Ring Attention aims to solve, is that the calculations are done sequentially in spite of their inherent symmetry. To solve this Ring Attention introduces a ring of devices (say GPUs), each of which correspond to a block of input tokens. Then each device only needs to compute the intra- and inter-block Attention values for its assigned block. This means that at initialization each device is given Key, Query, and Value matrices corresponding to its assigned block so that it can compute intra-block Attention. Next, to perform inter-block Attention the device needs Key and Value matrices from another block, and this is where we see the ring. The authors propose that each device send its current Key and Value matrices to the next device, while receiving new Key and Value matrices from the previous device, with the last device sending Key and Value matrices back around to the first device. As such each device will maintain the Query matrix of its assigned block, but will see the Key and Value matrices of all blocks.

It is worth noting that the transfer of Key and Value matrices is done in parallel to the actual Attention computation, with each device maintaining an input buffer that can receive and hold these matrices until the device is ready to use them. This means that as long as the Attention computation takes longer than the time to send these matrices to the next device in the ring, the communication time does not affect the overall run-time of the model. This is great because it means that the Attention computation is no longer quadratic with respect to the context window, but is now limited by the block size and the number of devices present in the ring. And while the next paper provides a key improvement upon Ring Attention, this is the true discovery that allows for such large context windows.
Striped Attention
Striped Attention is a follow-up to Ring Attention, aiming to exploit the use of Ring Attention in LLMs for performance gains. LLMs use a special version of Attention called Causal Attention, this essentially means that each token can “attend” to itself and the tokens that came before it. For those of you unfamiliar with this concept it can basically be thought of as forcing the model to read a sentence one word at a time rather than analyzing every word all at once. Mathematically this results in a triangular attention matrix with nearly half of the matrix now being zeros.

Each of these zeros present in the Causal Attention matrix is trivial to compute, taking very little time, however, these zeros are not equally balanced across the devices. In fact, the device assigned to the first block of tokens will only compute zeros for all steps involving intra-block Attention computations. This means that this first device will essentially be stuck waiting on all other devices to complete their jobs, creating a huge imbalance in computations done across each device.

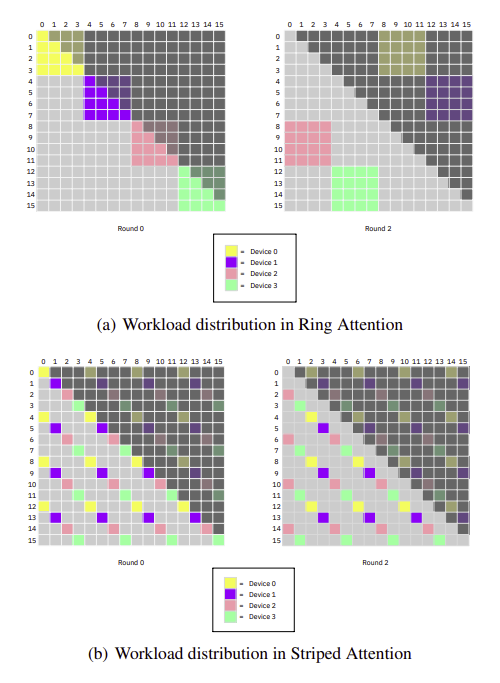
Striped Attention aims to take advantage of this inefficiency, attempting to perform “load balancing” across all zeros in the Attention computation such that each device is equally contributing at each step of the Attention computation. Striped Attention does this by changing the way token blocks are created. While Ring Attention naively splits the tokens using continuous grouping (i.e. the first K tokens are in block 1), Striped Attention creates groups by taking a token every N tokens, resulting in a every-other token style of block creation.
The result is that each Attention computation is much more saturated, allowing the ring of devices to more evenly take advantage of the trivial zero computation, therefore increasing the speed of computation. While this gain in performance is less revolutionary that Ring Attention is, it has provided a way for AI researchers to squeeze every last drop of performance from their compute budget, allowing them to even further increase the context window for a given compute budget.
While I feel the images can better illustrate why Striped Attention is an improvement over Ring Attention for Causal Attention computation, I still wanted to include the image below as it shows some of the true beauty of this method and provides some insight into the resulting attention computation.
Conclusion
The creation of Ring Attention and by extension Striped Attention has made scalable context much easier, allowing Attention computation to scale with the number of devices rather than scaling directly with the context size. This means that companies without any realistic device constraints such as Google, Meta, and Microsoft can take full advantage of these gains, creating models with nearly infinite context lengths. These nearly infinite context lengths have somewhat rendered Mamba and its Memory nearly irrelevant. While there are still some contexts where Mamba and SSMs can be applied, it is beginning to seem as though Language Modelling will be left to the Transformers for now.
If you enjoyed this post, I have quite a few more blog entries upcoming:
The Accidental Success of ChatGPT
Practical Programmable RAG Parts 1 and 2
Creating Mixture of Experts From Scratch
If any of these topics seem interesting to you consider following me on Medium or here on Substack (I post the same content to both platforms for free). I post twice a month on Mondays, covering topics such as AI research papers, AI philosophy, and AI programming projects.