



Detail Matters: Machine Learning’s Fast Attention Revolution through Level of Detail
How BASED uses “level of detail” to replace the Transformer as a language architecture.


Transformers have dominated general sequence modelling and natural language processing for almost 6 years through the use of self-attention, the act of adjusting the understanding of a word by analyzing all other words in the input. This simple concept of attending to all tokens in the input has proved powerful, allowing models to bypass the exploding/vanishing gradient problem and scale to billions of parameters with relative ease. By solving these problems the attention mechanism has served as the backbone for countless foundational models like BERT and GPT and causing massive leaps in performance in computer vision, natural language processing, and speech recognition tasks. Attention, however, does not come without its flaws, key among them, its quadratic inference time with respect to the input length. This inference time complexity has huge ramifications, leading to limited context windows, higher memory bottlenecks, and slower run times.
Modern research has sought to relax the constraints of attention in order to find an attention-like mechanism which can be computed in a sequential manner, thus reducing the runtime to be sub-quadratic in nature. Architectures such as RWKV and RetNet seek to remove non-linearities such as SoftMax from the standard attention mechanism in order to promote linear inference cost, however, these models have struggled to maintain the same performance that is shown by Transformer models on language modelling tasks. The decline in performance was thought to result from more rapid run-time, seen as an inherent trade-off in the context of the “Impossible Triangle.” According to this paradigm, a model can achieve two out of three objectives: being trained rapidly, demonstrating quick inference, or delivering high performance.

And research appeared to substantiate the notion of this “Impossible Triangle”, at least until the introduction of a novel model called BASED. BASED had managed to defeat the “Impossible Triangle” by maintaining fast parallel training while achieving sub-quadratic inference and exceeding Transformer model performance on smaller scale language models(~350 million parameters). This new model has been the first real hope for a Transformer replacement in the 6 years since the Transformer’s introduction, but there are still numerous experiments yet to be conducted on the BASED model, with a primary focus on scaling the model to billions of parameters. This article’s objective, however, is not to propose specific experiments to be run on BASED, instead, the aim is to delve into the intricate details of the relaxed attention mechanism employed by BASED. Hopefully providing an intuition for why the BASED model is so much more capable than its predecessors (RWKV, RetNet, and Linear Transformers) and why the model is capable of competing with Transformers on langauge modelling tasks.
Constructing BASED
The authors of BASED noticed a key pattern in all sub-quadratic attention imitation models, they all seemed to show pitiful Associative Recall (AR) performance, a sub-task which the Transformer naturally excelled at. Associative Recall is defined by the authors as recognition of infrequent word pairings such as first-last name pairs or city-state pairs that appear within text. Attention, and by extension Transformers, can do this quite easily as there is built in SoftMax attention “look-up” to previous tokens within the input. As such, the authors of BASED had to find a way to create an SoftMax attention-like mechanism that could maintain high AR performance. Many linear replacements for SoftMax were analyzed, including the Perfomer, cosFormer, and ReLU functions, however, the authors found that a simple Taylor Series approximation gave them the best results. The major difference between the Taylor approximation and other linear attention mechanisms is that the Taylor approximation was “spiky” rather than uniform, allowing tokens to properly attend to important sections of input rather than broadly attending to the entire input.
This “spiky” linear attention was combined with a short gated convolution, with the BASED model repeating these two modules in sequence to create the final autoregressive model. While the authors of BASED focus on providing intuition around the need for “spiky” attention, I believe that it is additionally important to intuitively understand the relationship between the gated convolution and linear attention modules. While one could interpret it as a division of tasks, with convolution adept at offering precise short-range information and linear attention excelling in providing sufficiently accurate long-range information, I find the conceptualization of the model as exhibiting “level of detail” to be more intuitive and intriguing.
Level of Detail
The concept of “level of detail” (LOD) is fundamental in various fields, encompassing computer graphics, data representation, modeling, and even decision-making processes. It refers to the degree of intricacy or granularity in the presentation or representation of information. The appropriate level of detail depends on the specific context, goals, and requirements of a particular task or system.
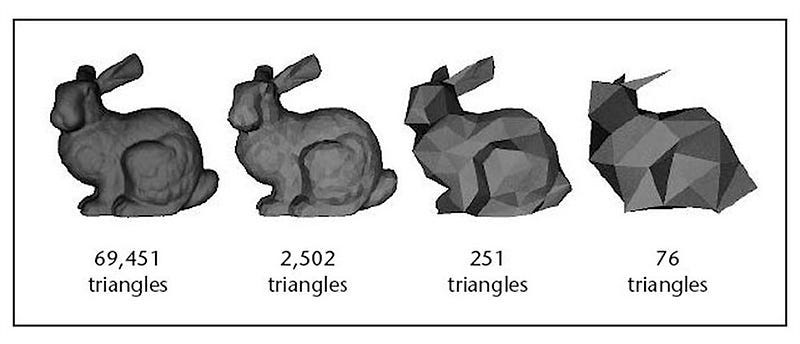
In computer graphics, LOD is crucial for optimizing the rendering of 3D models. As objects move closer or farther away from the viewer, their level of detail may be adjusted dynamically to maintain a balance between visual quality and computational efficiency. High levels of detail are necessary for objects close to the viewer, while lower levels suffice for those in the distance where minute details may not even be truly visible. This approach is especially vital in video games, simulations, and virtual reality applications to ensure smooth performance without sacrificing visual fidelity. Intuitively, this is exactly how humans look at and understand art, we switch between looking at the entire picture for global information and analyzing a small local area for all the little details. In this sense the global context is important but does not need to be exact as the local context will be able to fill in any gaps in understanding. This can even be thought of as peripheral vs. central vision, where the peripheral vision does not need to be crisp for you to see accurately, it only needs to be blurry so that you are able to add important context to what you are truly analyzing in your central vision.
In text processing the idea is much the same, information extraction for short-range interactions must be much more accurate as any slight deviation can lead to a huge misinterpretation of the text. During long-range interactions however, the information extracted just needs to be accurate enough to provide a “big picture” understanding of the interaction. This means that by employing LOD we can decrease the overall computation requirements while maintaining high accuracy performance. This may even imply that further optimizations to the LOD balance could provide further improvements upon the BASED model.
Conclusion
The value of the research being done by the Zoology team and their accomplishments with the BASED model cannot be overstated, and that is without any formal paper yet being published in regards to BASED. In the coming year we are likely to see the BASED model scaled up to much larger parameter sizes and there is likely to be tons of research that will analyze and interpret the inner workings BASED in order to provide an intuitive understanding similar to what we have with attention. While the authors early intuitions into why attention spikiness provides great results, it was easy to reflexively ask if the convolution module was necessary or if the spiky linear transformer would perform well enough on its own. While there is no empirical evidence to answer this question at the moment, the intuitive explanation of “level of detail” resonates as a strong justification for the dual module design, showing an unintentional imitation of how the human brain processes information.
The concept of “level of detail” in machine learning serves as a pivotal strategy to enhance model performance and comprehension across various domains. By incorporating different levels of detail, models gain the capability to focus on specific aspects of the input data, enabling them to discern intricate patterns and nuanced features. The flexibility of adjusting the level of detail empowers machine learning models to adapt to diverse tasks, striking a balance between precision and computation. This nuanced approach contributes to the robustness and versatility of machine learning systems, allowing them to excel in tasks that demand a comprehensive understanding of complex data.